Machine Learning for Anomaly Detection : A Comprehensive Guide
Machine learning for anomaly detection is a powerful technique used to identify unusual patterns or outliers in data that deviate significantly from the norm. These anomalies can indicate critical events such as fraud, security breaches, equipment failures, or errors in data.
Understanding Anomaly Detection
Anomaly detection, also known as outlier detection, is the identification of rare items, events, or observations which raise suspicions by differing significantly from the majority of the data. Machine learning algorithms play a vital role in automating this process, enabling efficient and accurate detection of anomalies in large datasets.
Types of Anomalies
- Point Anomalies: A single data point that is significantly different from the rest.
- Contextual Anomalies: A data point that is anomalous within a specific context.
- Collective Anomalies: A collection of data points that are anomalous as a group, even if individual points are not.
Understanding these types of anomalies is crucial for selecting the appropriate anomaly detection algorithms and techniques.

Machine Learning Approaches for Anomaly Detection
Several machine learning techniques can be applied to anomaly detection, each with its strengths and weaknesses. The choice of method depends on the nature of the data and the specific requirements of the application.
Supervised Learning for Anomaly Detection
In supervised learning, the model is trained on a labeled dataset containing both normal and anomalous data points. This approach requires a significant amount of labeled data, which can be challenging to obtain in real-world scenarios.
Common supervised learning algorithms used for anomaly detection include:
- Support Vector Machines (SVM)
- Decision Trees
- Neural Networks
Unsupervised Learning for Anomaly Detection
Unsupervised learning methods are used when labeled data is not available. These algorithms learn the normal patterns in the data and identify deviations from these patterns as anomalies.
Popular unsupervised learning algorithms for anomaly detection include:
- Clustering algorithms (e.g., K-Means, DBSCAN)
- One-Class SVM
- Autoencoders
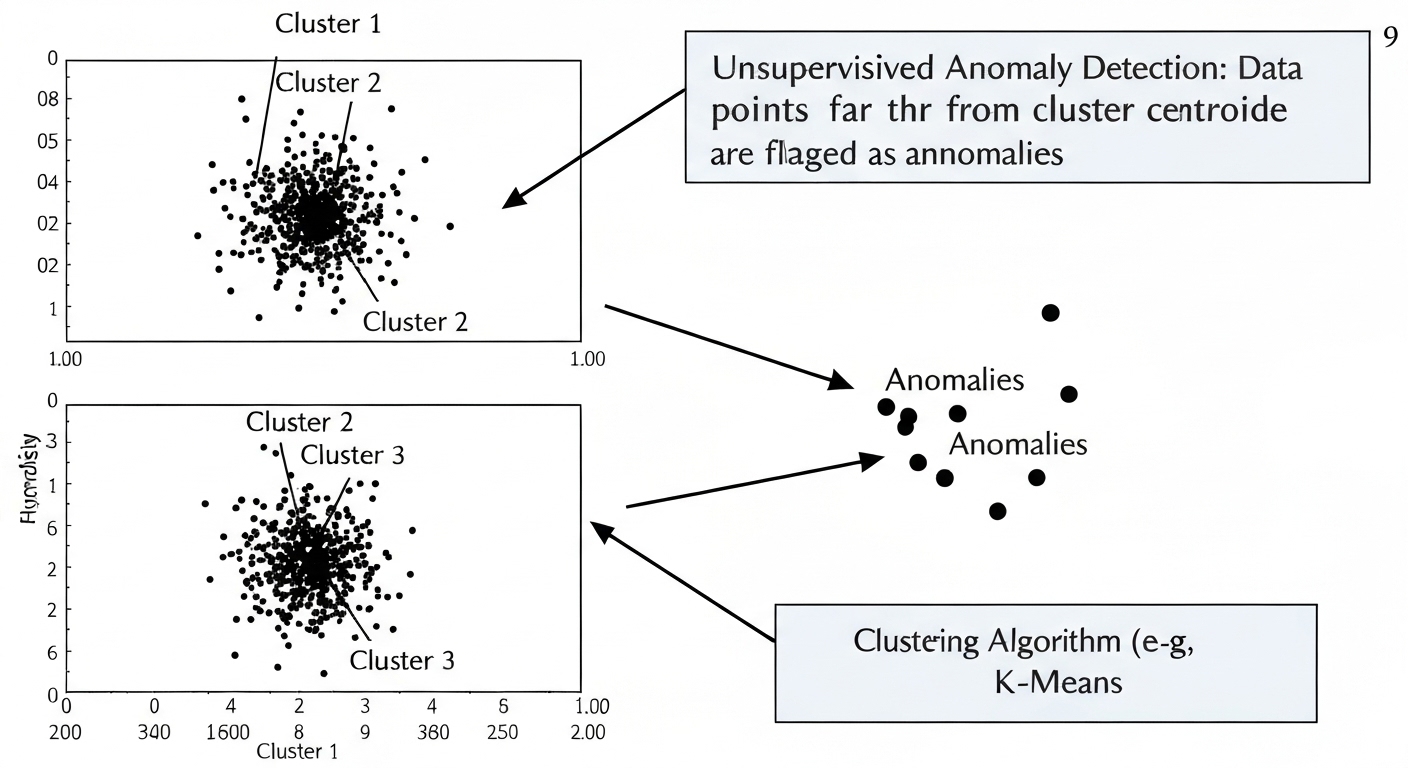
Semi-Supervised Learning for Anomaly Detection
Semi-supervised learning is a hybrid approach that uses a small amount of labeled data along with a larger amount of unlabeled data. This can be particularly useful when obtaining fully labeled datasets is difficult or expensive.
Techniques such as:
- Self-training
- Generative models
are commonly used in semi-supervised anomaly detection.
Applications of Machine Learning for Anomaly Detection
The versatility of machine learning for anomaly detection makes it applicable to a wide range of industries and use cases.
Fraud Detection
In the financial sector, fraud detection is a critical application. Machine learning algorithms can analyze transaction data to identify fraudulent activities such as credit card fraud, insurance fraud, and money laundering.

Intrusion Detection
Intrusion detection systems (IDS) use machine learning to monitor network traffic and system logs for suspicious activities that may indicate a cyberattack. These systems can identify anomalies such as unusual network traffic patterns, unauthorized access attempts, and malware infections.
Predictive Maintenance
In manufacturing and other industries, predictive maintenance utilizes machine learning to analyze sensor data from equipment and machinery. By detecting anomalies in this data, it is possible to predict potential failures and schedule maintenance proactively, reducing downtime and costs.
Healthcare Monitoring
Anomaly detection can be used in healthcare to monitor patient data for unusual patterns that may indicate a medical condition or adverse reaction to treatment. This can help healthcare providers to identify and respond to potential problems more quickly.
Data Preprocessing and Feature Engineering
Effective data preprocessing and feature engineering are essential for successful anomaly detection. These steps involve cleaning, transforming, and selecting relevant features from the data to improve the performance of the machine learning model.
Data Cleaning
Data cleaning involves handling missing values, removing duplicates, and correcting errors in the data.
Feature Scaling
Feature scaling ensures that all features have a similar range of values, preventing features with larger values from dominating the model.
Feature Selection
Feature selection involves selecting the most relevant features for anomaly detection, reducing the dimensionality of the data and improving model accuracy.
Model Evaluation and Performance Metrics
Evaluating the performance of an anomaly detection model is crucial to ensure that it is effectively identifying anomalies without generating too many false positives.
Precision and Recall
Precision measures the proportion of correctly identified anomalies out of all data points flagged as anomalies, while recall measures the proportion of actual anomalies that were correctly identified.
F1-Score
The F1-score is the harmonic mean of precision and recall, providing a balanced measure of the model’s performance.
AUC-ROC
Area Under the Receiver Operating Characteristic (AUC-ROC) curve is a measure of the model’s ability to distinguish between normal and anomalous data points.
Challenges and Future Directions
While machine learning for anomaly detection offers significant benefits, there are also several challenges to overcome. These include:
- Dealing with imbalanced datasets, where the number of normal data points far exceeds the number of anomalies.
- Handling high-dimensional data, where the number of features is very large.
- Adapting to evolving data patterns, where the characteristics of normal and anomalous data may change over time.
Future research directions in this field include developing more robust and scalable algorithms, exploring new techniques for feature engineering, and improving the interpretability of anomaly detection models.
Conclusion
Machine learning provides powerful tools for automating and improving anomaly detection across various domains. By understanding the different types of anomalies, selecting the appropriate machine learning techniques, and carefully preprocessing and evaluating the data, organizations can leverage anomaly detection to enhance security, prevent fraud, and improve operational efficiency. As artificial intelligence continues to evolve, we can expect even more sophisticated and effective solutions for machine learning for anomaly detection to emerge.
For further information, explore NIST, a leading authority on technology and standards.
Learn more about our services at flashs.cloud

FLASH CLOUD DEV AND MARKETING - PERFORMANCE
Copyright © 2024 flashs.cloud, All rights reserved



+84372 005 899
Consulting Hotline
Or Leave Your Phone Number So We Can Call You Back In A Few Minutes
HOTLINE
+84372 005 899