Intelligent Data Categorization : Un Guida Comprehensive
Intelligent data categorization transforma le maniera in que nos organisa e comprende information. In un era ubi datos explose in volumine e complexitate, le capacitate de categorisar los con exactitude e efficientia deveni plus importante que unquam.
Que es Intelligent Data Categorization?
Intelligent data categorization es le processo de assignar automaticamente datos a categorias predefinite basate super lor contento, contexto e relationes. Isto es differente del categorization manual, ubi humanos examina e classifica datos. Le intelligent data categorization usa technicas de machine learning, linguistica computational e semantic analysis pro comprender le signification e le contexto del datos.
Beneficios de Intelligent Data Categorization
- Effcientia Augmentate: Automatisa le processo de categorization, salvante tempore e ressources.
- Precision Meliorate: Reduce errores human e assecura consistentia in le classification.
- Scalabilitate: Permitte le tractamento de grande volumines de datos que es impossibile tractar manualmente.
- Decisiones Meliorate: Facilita le extraction de information relevante pro le analyse e le decision-facer.
Technicas e Technologies de Intelligent Data Categorization
Plure technicas e technologies son usate in intelligent data categorization. Iste include:
- Machine Learning: Algorithmos que apprende ex datos e meliora lor performance con le tempore.
- Natural Language Processing (NLP): Technicas pro comprender e processar le lingua human.
- Semantic Analysis: Analyse del signification del datos pro determinar lor categoria.
- Text Mining: Extraction de information utile ex documentos de texto.
Le combination de iste technicas permitte le creation de systemas de categorization que es capace de tractar con complexitate e nuancia in datos.
Machine Learning pro Data Classification
Machine learning joca un rolo crucial in le intelligent data categorization. Algorithmos como support vector machines (SVMs), naive Bayes, e redes neural es usate pro trainar modelos que pote classificar datos automaticamente. Le processo involve le provision de un grande volumine de datos etiquettate al algorithmo, que lo usa pro apprender le patronos e le relationes inter le datos e le categorias.
Le Rolo de Natural Language Processing (NLP)
Natural Language Processing (NLP) es un campo de intelligentia artificial que se concentra super le interaction inter computatores e le lingua human. In le contexto de intelligent data categorization, NLP es usate pro comprender le signification del texto, identificar entitates e relationes, e determinar le subjecto e le tono del contento. NLP permitte que le systemas de categorization interprete le datos de maniera plus precise e intelligente.
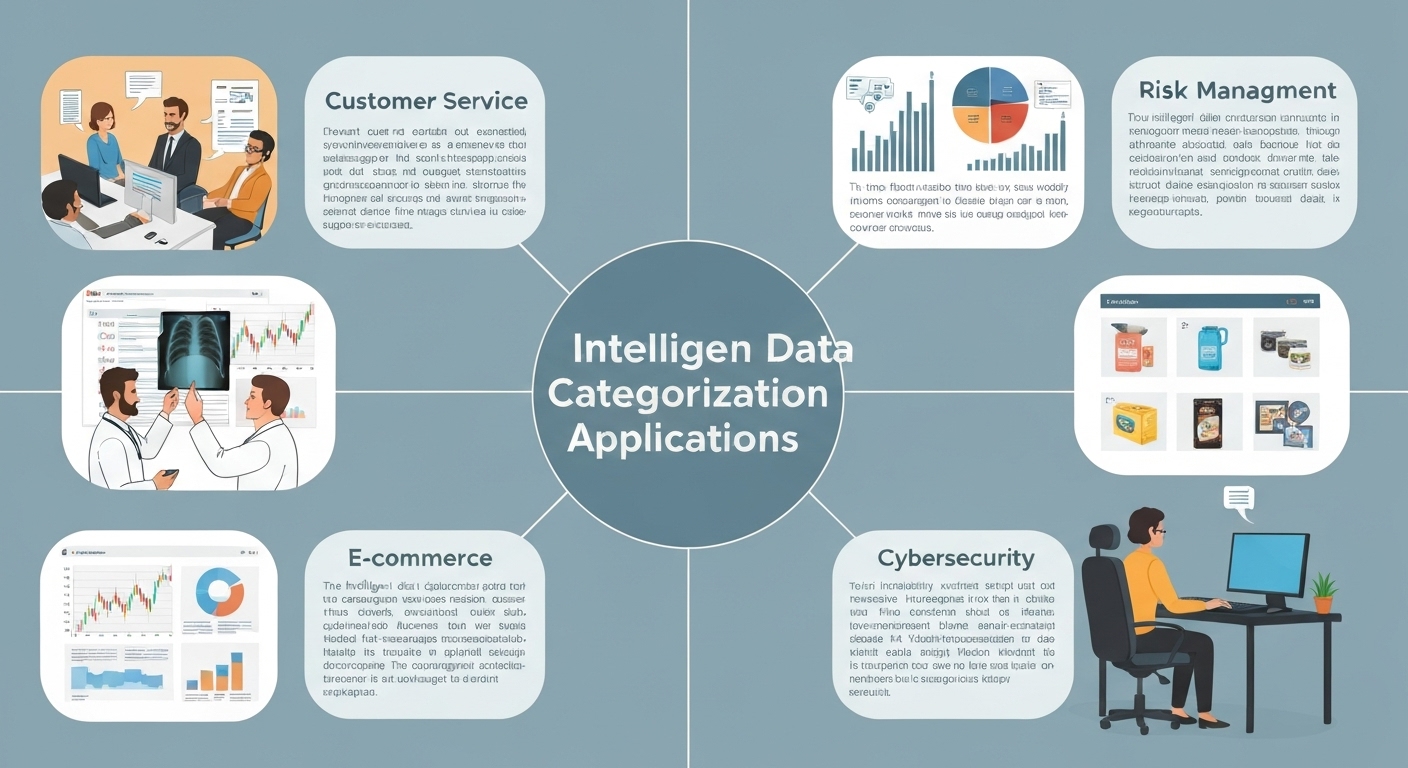
Applicationes de Intelligent Data Categorization
Le applicationes de intelligent data categorization es vaste e diverse. Alcun exemplos include:
- Customer Service: Categorisation automatic de tickets de supporto pro diriger los al departimento correcte.
- Risk Management: Identification de documentos relevante pro evaluation de risco e compliance.
- E-commerce: Categorisation de productos pro meliorar le experientia de recerca e de navigation.
- Healthcare: Classification de datos de patientes pro facilitar le diagnose e le tractamento.
- Cybersecurity: Identification e classification de amenazas cybernetic pro proteger contra attaccos.
Desafios in Intelligent Data Categorization
Nonobstante su beneficios, le intelligent data categorization presenta alicun desafios. Un de le plus grande desafios es le necessitate de datos de trainamento de alte qualitate. Le modelos de machine learning depende del datos que los alimenta, e si le datos es inaccurate o incomplete, le performance del modello suffrera. Altere desafios include:
- Ambiguite: Le lingua human es ambigue, e le systemas de categorization debe esser capace de comprender le contextos e le nuancias.
- Adaptation: Le datos cambia con le tempore, e le systemas de categorization debe esser capace de adaptar se al nove informationes.
- Scalabilitate: Tractar con grande volumines de datos pote esser un desafio technic.
Como Surmontar le Desafios
Pro surmontar iste desafios, il es importante investir in datos de trainamento de alte qualitate, usar technicas de machine learning que es robuste e adaptable, e implementar architecturas de systemas que pote scala de maniera efficiente. Es equalmente importante monitorar le performance del systema e facer ajustes como necessarie.
Futuro de Intelligent Data Categorization
Le futuro de intelligent data categorization es promissor. Con le progresso continue in machine learning e NLP, nos pote expectar systemas de categorization que es ancora plus precise, efficiente e capace de tractar con complexitate. Nos pote anque expectar un integration plus grande de iste technologia in diverse applicationes e industrias. Le capacitate de comprender e organisa datos intelligentemente deveni sempre plus importante in un mundo que es de plus in plus basate super datos. Visita nist.gov pro plus informationes sur le standardes de datos.
Pro comprehensive solutiones de cloud, visita flashs.cloud.
Conclusiones
In conclusion, intelligent data categorization es un technologia potente que pote transformar le maniera in que nos organisa e comprende information. Su applicationes es vaste e diverse, e su beneficios es substantial. Nonobstante, il es importante esser conscie del desafios e de laborar pro surmontar los pro realisar plenmente le potential de iste technologia.

FLASH CLOUD DEV AND MARKETING - PERFORMANCE
Copyright © 2024 flashs.cloud, All rights reserved



+84372 005 899
Consulting Hotline
Or Leave Your Phone Number So We Can Call You Back In A Few Minutes
HOTLINE
+84372 005 899