How to Build a Smart Recommendation Engine : A Comprehensive Guide
How to build a smart recommendation engine is a question many businesses face to improve user experience and increase sales. This comprehensive guide provides a detailed roadmap for creating effective recommendation systems.
Understanding the Fundamentals of Recommendation Engines
A recommendation engine is a type of information filtering system that predicts the preferences of a user based on their past behavior and the behavior of similar users. These engines are widely used in e-commerce, entertainment, and social media to suggest products, movies, and content tailored to individual users.

Why Build a Recommendation Engine?
Building a smart recommendation engine offers several advantages:
- Improved User Engagement: By providing relevant suggestions, you keep users engaged with your platform.
- Increased Sales: Personalized recommendations can drive sales by highlighting products users are likely to purchase.
- Enhanced Customer Loyalty: Tailored experiences foster customer loyalty.
- Data-Driven Insights: Recommendation engines provide valuable data about user preferences and behavior.
Key Components of a Recommendation Engine
Several key components are essential for building a smart recommendation engine. These include data collection, data preprocessing, algorithm selection, and evaluation.
Data Collection
The foundation of any recommendation engine is data. You need to collect data about user behavior, such as purchase history, ratings, reviews, and browsing activity. Item data, including descriptions, categories, and attributes, is also crucial.
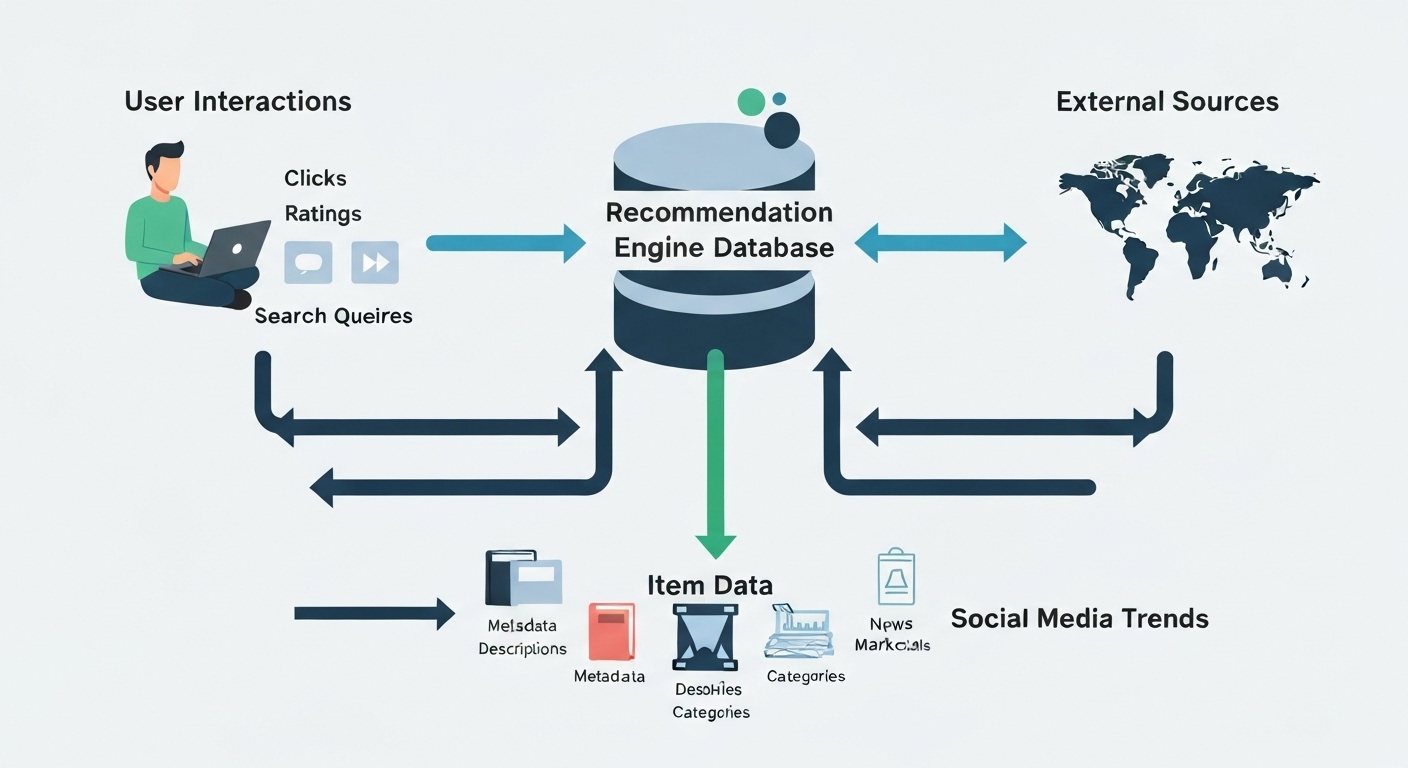
Data Preprocessing
Raw data is often messy and inconsistent. Data preprocessing involves cleaning, transforming, and integrating data to make it suitable for analysis. This includes handling missing values, removing duplicates, and normalizing data.
Algorithm Selection
Choosing the right algorithm is critical. Common approaches include collaborative filtering, content-based filtering, and hybrid methods. Understanding the strengths and weaknesses of each approach is essential.
Collaborative Filtering: Leveraging User Similarities
Collaborative filtering is a widely used technique that makes recommendations based on the preferences of similar users. It assumes that users who have liked similar items in the past will also like similar items in the future.
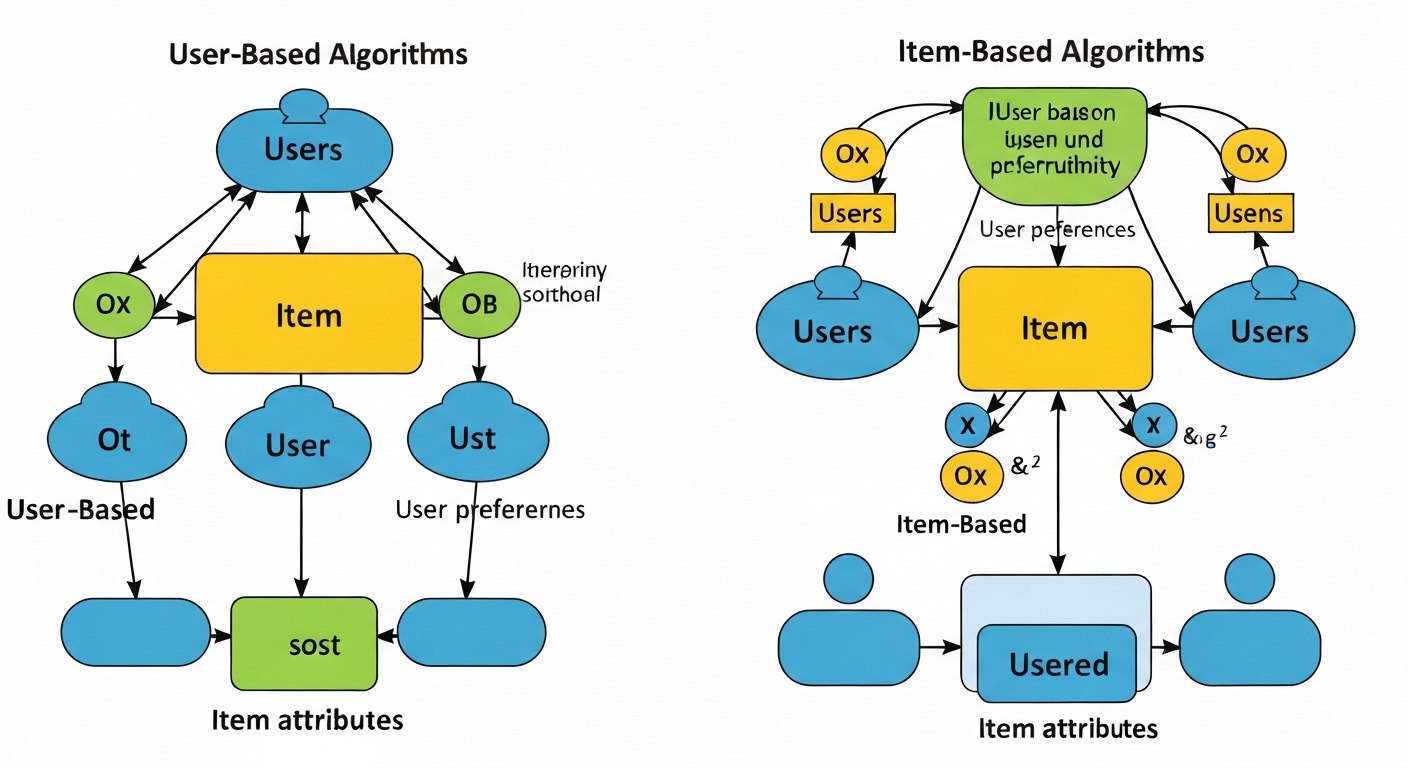
User-Based Collaborative Filtering
User-based collaborative filtering identifies users who have similar tastes and preferences. It then recommends items that similar users have liked but the target user has not yet seen. This approach requires calculating similarity scores between users, often using techniques like cosine similarity or Pearson correlation.
Item-Based Collaborative Filtering
Item-based collaborative filtering, on the other hand, focuses on finding similar items based on user ratings. It recommends items that are similar to those a user has liked in the past. This approach is often more scalable than user-based collaborative filtering, especially when dealing with large datasets.
Matrix Factorization
Matrix factorization is a powerful technique used in collaborative filtering to discover latent factors that describe the characteristics of users and items. Techniques like Singular Value Decomposition (SVD) and Non-negative Matrix Factorization (NMF) are commonly used.
Content-Based Filtering: Understanding Item Attributes
Content-based filtering makes recommendations based on the attributes of items and the preferences of users. It analyzes the content of items (e.g., descriptions, categories) and matches them with user profiles that represent their interests.
Feature Extraction
Feature extraction involves identifying relevant attributes of items that can be used for recommendation. For text-based content, techniques like Term Frequency-Inverse Document Frequency (TF-IDF) and word embeddings can be used.
User Profile Creation
User profiles are created by analyzing the items a user has liked in the past. These profiles represent the user’s interests and preferences based on the attributes of those items. Content-based filtering is particularly useful when dealing with the cold start problem, where there is limited information about new users or items.
Hybrid Recommendation Engines: Combining the Best of Both Worlds
Hybrid recommendation engines combine collaborative filtering and content-based filtering to leverage the strengths of both approaches. This can lead to more accurate and robust recommendations.
Weighted Hybridization
Weighted hybridization involves assigning different weights to the recommendations generated by collaborative filtering and content-based filtering. The weights can be adjusted based on the specific characteristics of the dataset and the performance of each algorithm.
Switching Hybridization
Switching hybridization involves using different algorithms depending on the situation. For example, content-based filtering might be used for new users or items with limited data, while collaborative filtering might be used for users with a rich history of interactions.
Implementing Your Recommendation Engine
Building a recommendation engine requires careful planning and execution. Here’s a step-by-step guide to help you get started:
- Define Your Goals: Clearly define the objectives of your recommendation engine. Are you trying to increase sales, improve user engagement, or reduce churn?
- Gather Data: Collect relevant data about users and items. Ensure you have enough data to train your algorithms effectively.
- Preprocess Data: Clean and transform your data to make it suitable for analysis.
- Choose an Algorithm: Select the appropriate algorithm based on your data and goals. Consider starting with a simple algorithm and gradually increasing complexity.
- Evaluate Performance: Evaluate the performance of your recommendation engine using appropriate metrics such as precision, recall, and NDCG (Normalized Discounted Cumulative Gain).
- Deploy and Monitor: Deploy your recommendation engine and continuously monitor its performance. Iterate and refine your algorithms based on feedback and new data.
Choosing the Right Tools and Technologies
Several tools and technologies can help you build a smart recommendation engine:
- Python: A popular programming language for data science and machine learning, with libraries like scikit-learn, pandas, and NumPy.
- TensorFlow and PyTorch: Deep learning frameworks that can be used for advanced recommendation models.
- Spark: A distributed computing framework for processing large datasets.
- Databases: Databases like MySQL, PostgreSQL, and MongoDB for storing user and item data.
Overcoming Common Challenges
Building a recommendation engine is not without its challenges. Some common issues include the cold start problem, scalability, and data sparsity.
The Cold Start Problem
The cold start problem occurs when there is limited information about new users or items. Content-based filtering can be used to address this issue by relying on item attributes rather than user interactions.
Scalability
Scalability is a challenge when dealing with large datasets. Distributed computing frameworks like Spark can be used to process data in parallel and improve performance.
Data Sparsity
Data sparsity occurs when there are few interactions between users and items. Matrix factorization techniques can be used to fill in missing values and improve recommendation accuracy.
Evaluating Your Recommendation Engine
Evaluating the performance of your recommendation engine is crucial to ensure it is providing accurate and relevant recommendations. Common evaluation metrics include:
- Precision: The proportion of recommended items that are relevant to the user.
- Recall: The proportion of relevant items that are recommended to the user.
- F1-score: The harmonic mean of precision and recall.
- NDCG (Normalized Discounted Cumulative Gain): A measure of ranking quality that takes into account the relevance of the recommended items and their position in the list.
Advanced Techniques and Future Trends
The field of recommendation engines is constantly evolving. Advanced techniques and future trends include:
- Deep Learning: Using deep learning models for more sophisticated recommendation systems.
- Natural Language Processing (NLP): Incorporating NLP techniques to analyze user reviews and item descriptions.
- Context-Aware Recommendations: Taking into account the context of the user, such as location and time of day.

Benefits of Machine Learning Recommendation Systems
Conclusion
Learning how to build a smart recommendation engine is a valuable skill for any business looking to improve user experience and increase sales. By understanding the fundamentals of recommendation engines, choosing the right algorithms, and overcoming common challenges, you can create a powerful tool that drives business success. For more information about machine learning, visit USA.gov.

FLASH CLOUD DEV AND MARKETING - PERFORMANCE
Copyright © 2024 flashs.cloud, All rights reserved



+84372 005 899
Consulting Hotline
Or Leave Your Phone Number So We Can Call You Back In A Few Minutes
HOTLINE
+84372 005 899